


Abstract
Comparisons of the same patient data in 2004 and 2006 downloads of the DIN-LINK UK primary care database demonstrated unexpected differences in the rates of coronary heart disease between the datasets. Incidence rates were lower between 1996–2003 in the new (2006) download. Patient record checks demonstrated that coronary heart disease codes had been removed in the new download during the run-up to the new contract. Planners need to be aware of such issues when evaluating trends in CHD or other similar conditions.
INTRODUCTION
Accurate estimates of disease incidence and prevalence are essential for planning public health policy. The UK has increasingly used aggregated data from GP computer systems to produce such estimates.1 Since a new national contract for UK GPs was announced in February 2003,2 local prevalence of many chronic diseases has been a matter of particular interest to GPs. The Quality and Outcomes Framework (QOF) described in the contract links income to performance against multiple targets in chronic disease monitoring and management, encouraging accurate identification of patients with such diseases. This is further encouraged by a prevalence adjustment factor that affects remuneration if individual practice's disease prevalence rates greatly differ from the average of all the practices in the scheme.3,4 Practices were encouraged to ensure that their data were as accurate as possible in the run-up to contract implementation.
Using data from a large primary care database, trends in incidence of coronary heart disease in UK general practice over the period preceding and during the introduction of the new contract are described. This study also examines how changes made to records during the introduction of the new contract influenced these trends.
METHOD
DIN-LINK is an on going anonymised computerised primary care database including practices from all parts of Britain.5 Practices provide data in anonymised form for epidemiological and market research purposes. Prevalence rates for a wide range of conditions including coronary heart disease,6 diabetes,7 atrial fibrillation,8 and common childhood diagnoses9,10 have been shown to compare well with other national data sources. The copy of DIN-LINK used by the authors of this paper is updated periodically by means of complete downloads of the whole database. Two separate downloads of all data — in early 2004 (old) and early 2006, (new) were compared: data from 111 practices providing high quality data between 1996 and 2003 in both downloads were studied. This represents 111 of the 131 practices running Synergy or System 6000 software in the 2004 download.
In each year the denominator was patients registered on 31 December for at least 6 months who had no coronary heart disease codes in earlier years. The incidence rates of coronary heart disease between 1996–2003, on the same patients in both downloads were calculated. That patients were the same was verified by a unique, but otherwise uninformative, identifier, which remains constant between versions of the database. Discrepancies between versions were investigated by examining printouts of individual patient records and frequencies of particular coronary heart disease codes in each database. Finally, the rates in patients still registered in a practice on 31 December 2003 and in those no longer registered were compared. All data manipulations and analyses were carried out using SAS version 9.1 for Solaris (SAS Institute, Cary, NC).
RESULTS
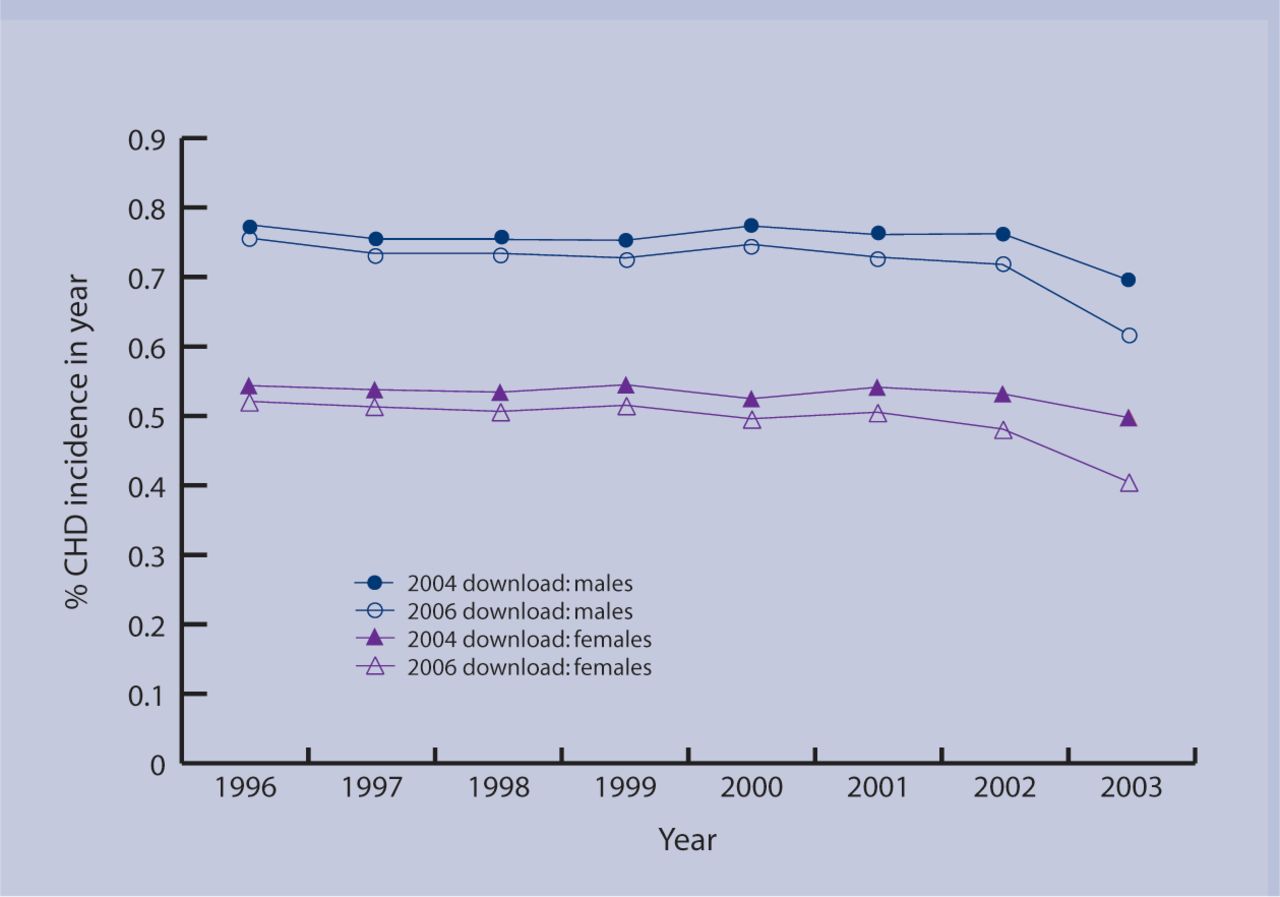
As expected, the new (2006) download was highly comparable with the old (2004) download. However, coronary heart disease incidence rates in the new download were consistently lower than in the old download, the difference being fairly constant from 1996 to 2000, but with the two versions diverging from 2001 onwards (Figure 1). In 2003, incidence rates from the new download were only 81% (women) and 89% (men) of the rate from the old download (Table 1). Therefore, of the women with newly diagnosed coronary heart disease in 2003 according to the old download, 18% (240/1303) were no longer identified as having coronary heart disease in the new download. For men it was 11% (184/1651). This deletion of codes was a generalised one and was not restricted to a small number of practices; 91 of the 111 practices showed at least one discrepancy in incidence in 2003.
{kind=link}
CHD incidence between 1996-2003 in the DIN-LINK 2004 and 2006 downloads.
Coronary heart disease incidence between 1996–2003 in the DIN-LINK 2004 and 2006 downloads.
The prevalence of coronary heart disease (effectively a measure of cumulative incidence since once diagnosed subjects do not recover) rose steadily from 1996 to 2003 in the old download, rising more slowly in the new download until 2002, and then falling slightly (data not shown). Comparison of individual records in the two downloads, and frequency distributions of specific coronary heart disease codes by year, indicated that coronary heart disease codes were being deleted (or replaced by codes such as ‘chest pain’) from some patient records in the new download. This deletion of coronary heart disease codes was primarily among patients remaining registered in 2003, and particularly those with no corroborative evidence (such as specific treatments) to support a diagnosis of coronary heart disease. When patients were divided into two groups depending on whether they remained registered with a practice on 31 December 2003, it was apparent that nearly all discrepancies occurred among those still registered (Supplementary Table 1). Of the 230 code discrepancies in 2002 (for men and women combined) only two occurred in patients not registered on 31 December 2003; of the 97 discrepancies in 1996 only three were in patients not registered.
How this fits in
Aggregated GP data are increasingly used to inform public health policy. This study shows the influence that policy may have on the collection of aggregated GP data.
DISCUSSION
Clear evidence was identified that during 2004–2005 GPs throughout the country retrospectively altered coronary heart disease codes in patients who were still registered during 2003. It seems certain that this resulted from the introduction of the new GP contract quality targets, for the following reasons:
The divergence between the database versions started around 2002 and became most apparent in 2003, coinciding with publication of the QOF.
Patients still registered in 2003 were far more likely to have their records altered than patients who were not still registered by 2003.
It appeared to be patients with no other corroborative data to confirm coronary heart disease that had their codes removed or altered to ‘chest pain’ or similar.
By 2003, patients were less likely to be assigned a coronary heart disease code, suggesting that GP's were ensuring that diagnoses were confirmed.
This finding is important because primary care databases are increasingly used to inform policy. However, this study's data demonstrate that policy also influences data recording, including retrospective changes. Aggregated primary care databases are unlikely to download audit trails where data are retrospectively incorporated into them. In the situation where an existing database is constantly being updated, the audit trail will be apparent when code changes are downloaded. However, an audit trail of such changes is unlikely to be maintained as part of the main database because they are complex and consume space. Researchers are likely to be unaware of them and these findings could easily have been missed. This also has implications for the electronic transfer of records between clinical systems since audit trails are often deleted at such times.
It seems that the new contract triggered a major data cleaning exercise in UK general practice. Although a few correct, but unsubstantiated diagnoses will have been removed, in the main, incorrect coronary heart disease diagnoses will have been removed, as codes were deleted primarily from those with no corroborative evidence, such as specific treatment, to support a diagnosis of coronary heart disease. GPs have the option of listing patients who refuse investigation or treatment from their QOF target list by using exception reporting.11 The overall effect should be to improve the accuracy of estimates of incidence and prevalence in future, as it appears that QOF has made practitioners more cautious about entering diagnostic labels without evidence, and has encouraged the use of symptom codes (in this case chest pain) when the patient initially presents.
However, such changes have major implications for analysis of trends using any of the aggregated computer databases. Coronary heart disease is only one of many chronic conditions included in the QOF. Researchers and public health planners will need to be aware of these issues, especially when assessing the influence of large scale interventions on these conditions, including the effectiveness of the QOF itself.
Although these issues are of particular importance to UK researchers, they will be of international interest as the QOF is recognised as a major player among quality improvement measures,12 and comparisons with US,11 European, and African models13 have already been made.
Supplementary Material
Acknowledgments
We are grateful to Cegedim Strategic Data (Chertsey, Surrey, UK) for their technical assistance with DIN-LINK database and for much helpful support. We acknowledge with gratitude the support of GPs who provide data for DIN-LINK.
Notes
Supplementary information
Additional information accompanies this article at http://www.rcgp.org.uk/bjgp-suppinfo
Funding body
This work was funded by a grant from the BUPA Foundation
Ethics committee
This study was approved by the National Heath Service Research Ethics Committee for Wandsworth (reference 05/Q0803/162)
Competing interests
The authors have stated that there are none
- Received July 4, 2004.
- Revision received September 23, 2004.
- Accepted November 30, 2006.
- © British Journal of General Practice, 2007.
In this issue









Jump to section
Keywords
More in this TOC Section
Related Articles
Cited By...

