


Abstract
Background Validated risk equations are currently recommended to assess individuals to determine those at ‘high risk’ of cardiovascular disease (CVD). However, there is no longer a risk ‘equation of choice’.
Aim This study examined the differences between four commonly-used CVD risk equations.
Design and setting Cross-sectional analysis of individuals who participated in a workplace-based risk assessment in Carmarthenshire, south Wales.
Method Analysis of 790 individuals (474 females, 316 males) with no prior diagnosis of CVD or diabetes. Ten-year CVD risk was predicted by entering the relevant variables into the QRISK2, Framingham Lipids, Framingham BMI, and JBS2 risk equations.
Results The Framingham BMI and JBS2 risk equations predicted a higher absolute risk than the QRISK2 and Framingham Lipids equations, and CVD risk increased concomitantly with age irrespective of which risk equation was adopted. Only a small proportion of females (0–2.1%) were predicted to be at high risk of developing CVD using any of the risk algorithms. The proportion of males predicted at high risk ranged from 5.4% (QRISK2) to 20.3% (JBS2). After age stratification, few differences between isolated risk factors were observed in males, although a greater proportion of males aged ≥50 years were predicted to be at ‘high risk’ independent of risk equation used.
Conclusions Different risk equations can influence the predicted 10-year CVD risk of individuals. More males were predicted at ‘high risk’ using the JBS2 or Framingham BMI equations. Consideration should also be given to the number of isolated risk factors, especially in younger adults when evaluating CVD risk.
INTRODUCTION
Cardiovascular disease (CVD) remains the leading cause of mortality in the UK, with the latest statistics documenting that almost one-third of all deaths are currently attributed to the condition.1 Current UK government guidelines implemented through the National Institute for Health and Care Excellence (NICE) advocate risk assessment of individuals aged 40–74 years to identify those at ‘high risk’ (≥20% 10-year risk of developing CVD).2 Early identification of individuals at elevated risk is essential so that lifestyle modification or pharmacological interventions can be prescribed to alleviate the risk of disease.3 It is recommended that validated equations should be used to assess CVD risk and up until February 2010, the Framingham Risk Equation4 was the ‘equation of choice’ before this endorsement was withdrawn.2 The amended NICE guidelines now encourage healthcare professionals to use the cardiovascular risk equation that they feel most appropriate.2,5
Previous research has highlighted differences in false-positive rates (at a 20% threshold) between six widely cited CVD risk algorithms,6 despite these differences the screening performance of the six was similar. It was concluded that age remains the most dominant predictor in CVD events despite individual risk factors being present.6 This observation is somewhat surprising, especially as 80% of all premature coronary heart disease in males can be attributed to the combination of smoking, hypertension, and high levels of total cholesterol (>5.2 mmol/l).7 In further terms of CVD risk factors, there is evidence that a multifactorial strategy treating glycaemic control, lipid profiles, and blood pressure together through either medication or behavioural therapy has been shown to be highly effective in reducing cardiovascular mortality compared with conventional treatment.8
Statin therapy is recommended as part of the management strategy for primary prevention of CVD for adults at high risk of developing CVD.2,9 Treatment should be initiated with simvastatin (40 mg) in those adults who have a ≥20% 10-year risk of developing CVD.2 Therefore, any differences between predicted risk equations could have a number of implications for the correct treatment of individuals (such as either over- or underprescribing statins as a primary treatment) and the associated costs of medications.
How this fits in
Up until February 2010 the ‘equation of choice’ of NICE to determine cardiovascular disease (CVD) risk was the Framingham Risk Equation, with the guidance now encouraging healthcare professionals to adopt the equation that they deem ‘most appropriate’. This research compares four commonly-used CVD risk equations in the UK and examines the number of individuals predicted at ‘high risk’. The JBS2 and Framingham BMI equations predicted a higher proportion of individuals at ‘high risk’ of CVD than the Framingham Lipids or QRISK2 algorithms. Furthermore, despite changes in absolute risk prediction after age stratification in all of the equations, there are few differences between isolated risk factors.
This study primarily compared four commonly-used CVD risk equations when the same individual dataset was applied, and examined if isolated risk factors translated to ‘high risk’ of CVD.
METHOD
Study population
All participants in this study were employees of either the local health board or steel workers within the Welsh region of Carmarthenshire who had received a CVD risk assessment as part of the established Prosiect Sir Gâr workplace-based initiative.10 The initiative was introduced in 2009 and data collection for this study took place between 2009 and 2012. All current employees aged >40 years (if white), or >25 years (if South Asian) with no prior diagnosis of CVD or diabetes were invited to participate in the project. In total, 790 employees accepted the invitation of a health assessment, of which 474 were females and 316 males.
Baseline measurements and risk prediction equations
According to a standard operational policy (SOP), all recruited individuals attended a standardised health assessment appointment with an occupational health nurse which lasted 30–40 minutes. During the session, demographic (date of birth, sex, and postcode of residence) and anthropometric (body mass and height) data were collected. Systolic and diastolic blood pressure, pulse rate and rhythm, smoking status, and family and medical histories were also recorded. Blood samples were also collected via capillary puncture and analysed immediately for total cholesterol (TC), high-density-lipoprotein cholesterol (HDL) and triglycerides (Cholestech LDX® System, Alere Inc., Orlando, FL). Ten-year predicted CVD risk was calculated by entering the relevant variables into the QRISK2,11 Framingham Lipids,12 Framingham BMI,12 and the Joint British Societies 2 (JBS213) risk equations.
Data analysis
The focus of analysis within this study was to compare four validated and routinely used CVD risk equations. Within the analysis, samples were stratified by age. Statistical analysis was performed using SPSS software (version 19) with significance set at P<0.05. Normality of data was assessed by a one-sample Kolmogorov-Smirnov test. Homogeneity of variance was determined by Levene’s statistic and one-way analysis of variance (ANOVA) with post-hoc Bonferroni or Tamhane’s T2 correction factor used to locate any differences within groups. χ2 analysis with α set at 0.05 was performed to analyse discrete data variables. Diastolic blood pressure data are represented as mean ± standard deviation. Body mass index (BMI), systolic blood pressure, triglyceride concentrations, QRISK2, Framingham Lipids, and Framingham BMI scores did not have a normal distribution. These datasets were consequently log transformed for analysis and represented as the geometric mean and approximate standard deviation. Age, TC:HDL ratio, and JBS2 scores did not have a normal distribution after log transformation and these data are represented as median and interquartile range. Kruskal–Wallis and Mann-Whitney tests were used to analyse JBS2 data.
RESULTS
All age baseline analysis
Table 1 shows the baseline risk characteristics and predicted all age 10-year CVD risk of the two sex cohorts. Although no statistical comparisons were made between the sexes, the table clearly illustrates a number of interesting observations. Despite the two cohorts being of similar age, BMI values, systolic and diastolic blood pressure readings, lipid profiles (TC:HDL ratio), triglyceride concentrations, and 10-year predicted CVD risk in each of the equations are all greater in the male cohort compared with the females. There was also a greater proportion of male individuals who reported being current smokers and who were presently prescribed antihypertensive medication. Furthermore, in each of the sex cohorts the all-age predicted CVD risk value was different dependent on which risk equation was adopted.
Baseline risk characteristics of female and male cohorts
Ten-year CVD risk prediction after age stratification
Table 2 and Figure 1 illustrate the 10-year predicted CVD risk for QRISK2, Framingham Lipids, Framingham BMI (Figure 1), and JBS2 (Table 3) after age stratification of the data into five predetermined age ranges (<45 years, 45–49 years, 50–54 years, 55–59 years, and ≥60 years). Figure 1 demonstrates that predicted 10-year CVD risk increased concomitantly with age in each of the risk equations for both sexes. Female predicted risk increased from 0.8±0.2% to 8.1±1.3% (QRISK2), 1.4±0.3% to 5.0±0.8% (Framingham Lipids), and 2.6±0.4% to 9.6±1.2% (Framingham BMI). In the male cohort, CVD risk estimation increased from 2.8±0.8% to 16.0±2.1% (QRISK2), from 5.3±1.2% to 16.4±2.5% (Framingham Lipids), and from 6.7±1.1% to 22.1±1.8% (Framingham BMI). In addition, at each age range, the Framingham BMI risk equation predicted individuals to be at a higher risk than either the QRISK2 or Framingham Lipids algorithms. In the male cohort the Framingham Lipid equation also predicted individuals at a higher risk than QRISK2 up until 60 years old. Of interest, in the female cohort, in the two youngest age ranges (<45 years and 45–49 years), Framingham Lipids estimated risk to be higher than QRISK2; however, in the latter two age ranges (55–59 years and ≥60 years) this relationship was reversed. In Table 3, the JBS2 median and interquartile ranges are displayed. The female predicted risk again increased concomitantly with age from 2% (1–3%) to 8.5% (7–14%) and the male cohort predicted risk increased from 7% (4–11%) to the peak value of 20% (12–25%) in the 55–59 years age range.

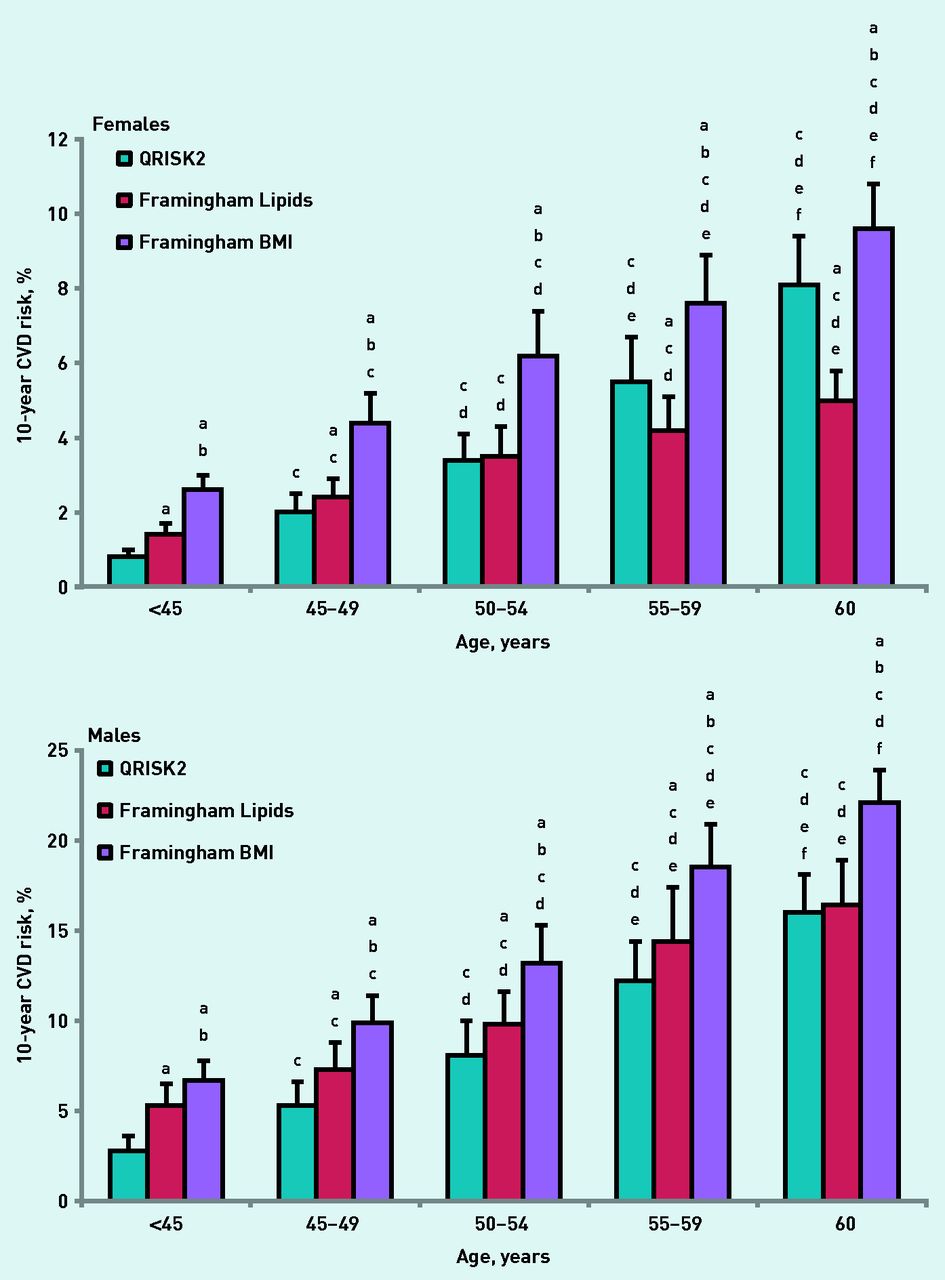{kind=link}
Changes in predicted 10-year CVD risk after age stratification after adoption of QRISK2, Framingham Lipids, and Framingham BMI risk equations. The graphs illustrate female and male cohorts. adenotes difference from QRISK2 (P<0.05). b denotes difference from Framingham Lipids (P<0.05). c denotes difference from <45-year age group (P<0.05). d denotes difference from 45–49-year age group (P<0.05). e denotes difference from 50–54-year age group (P<0.05). f denotes difference from 55–59-year age group (P<0.05).
Proportion of individuals categorised by risk category (low [<10%], intermediate [10–19.9%], or high [≥20%]) after prediction by different CVD risk equations
Changes in risk score predicted by JBS2 equation after age stratification
Individuals predicted at different risk classifications
Table 2 illustrates individuals categorised by low, intermediate, or high 10-year CVD risk after adoption of the four different equations. The number of women predicted at high risk was relatively low irrespective of which risk equation was adopted. The JBS2 equation predicted the greatest number of females at high risk (10 individuals), but this still only equated to 2.1% of the female cohort. Of note, no females were predicted to be at high risk when the Framingham Lipids risk score was used. However, the Framingham BMI and JBS2 tools resulted in a greater number of females at intermediate risk and fewer at low risk than either QRISK2 or Framingham Lipids. The JBS2 equation also predicted more females at intermediate risk and fewer at low risk than the Framingham BMI. Within the male cohort, the same relationship was observed, with the Framingham BMI and JBS2 equations predicting more males at intermediate and fewer at lower risk than the two other equations. The QRISK2 algorithm predicted the greatest number of males at low risk and this proportion was significantly lower than the three other algorithms. Unlike the female cohort, the differences between numbers of male individuals predicted at high risk are clearly apparent. The male JBS2 discrepancies in high risk prediction are most prominent, with 1 in 5 males categorised at high risk compared with 1 in 20, 1 in 12, and 1 in 8 using QRISK2, Framingham Lipids, and Framingham BMI, respectively.
Analysis of isolated risk factors and ‘high risk’ individuals after age stratification
Table 4 details the examination of isolated risk factors and amount of individuals predicted to be at ‘high risk’ of 10-year CVD after age stratification, which further uncovered a number of interesting observations. In the female cohort, there was a greater prevalence of females with high concentrations of total cholesterol from age ≥50 years; however, this was not reflected in a larger proportion of females observed to have dyslipidaemia. In all age groups except those aged <45 years, over one in five females were found to have systolic hypertension; however, only the JBS2 risk equation predicted any differences between ‘high risk’ females in the latter two age groups (55–59 years and ≥60 years). In the male cohort, the only differences between isolated risk factors were observed in a greater prevalence of systolic hypertension after age 55 years, and in high total cholesterol concentrations in the 55–59 years compared with the 50–54 years group. Despite very few differences between isolated risk factors, a higher proportion of males were predicted to be at ‘high risk’ of CVD in older age groups (50–54 years, 55–59 years, ≥60 years) in each of the four risk equations, except those aged 50–54 years for Framingham Lipids.
The prevalence of isolated risk factors and proportion of individuals categorised as ‘high risk’ after age stratification
DISCUSSION
Summary
This study compared CVD risk prediction when the same dataset was applied to four commonly-used risk equations. The main finding from this investigation is that adoption of the JBS2 or Framingham BMI equations predicts more individuals at absolute risk and ‘high risk’ than either QRISK2 or Framingham Lipids. This observation was more evident in male prediction using either the Framingham BMI or JBS2 risk equations, where 13.6% and 20.3% of males, respectively, were predicted to be at high risk of CVD compared with only 8.2% (Framingham BMI) and 5.4% (QRISK2). Up to a four-times greater cost would be associated with statin prescription, therefore, if the Framingham BMI or JBS2 risk equations were used instead of QRISK2. In addition, more males were predicted to be at ‘high risk’ of CVD in the older age groups despite very few differences between the prevalence of isolated risk factors. It appears that age remains more important than isolated risk factors when determining those individuals at ‘high risk’, irrespective of which risk equation is adopted.
Strengths and limitations
One of the strengths of this research is that the study population is based on an undiagnosed cohort, representative of the working demographic in Carmarthenshire, south Wales. If not for the Prosiect Sir Gâr initiative, these data would not be routinely available. All of the risk engines in this study accounted for sex, age, and systolic blood pressure, with all but the Framingham BMI equation incorporating the TC:HDL ratio. It was feasible, therefore, to make comparisons between the four prediction tools. The Framingham BMI equation requires the fewest clinical measurements of the four equations compared with only systolic blood pressure incorporated into the prediction algorithm. Another merit to the Framingham BMI is that a number of CVD risk factors, such as elevated non-HDL cholesterol, reduced HDL cholesterol, and hypertension, are influenced by obesity,14 and, furthermore, obesity is an independent risk factor for fatal coronary events.15 It is acknowledged that there are other risk equations available that may have been pertinent to this dataset. For example, the Scottish ASSIGN16 prediction model or the SCORE17 equation based on a European population could have been relevant to the study population. One of the advantages of the ASSIGN model is the inclusion of social deprivation; however, this deprivation is based on Scottish postcodes and would not be applicable to the present Welsh dataset, which is why the QRISK2 model was chosen instead which also incorporates social deprivation. The risk equations chosen for comparison in this study also account for non-fatal CVD unlike the SCORE equation, which is why this risk equation was not chosen for analysis. The only other limitation to this research could be that the cohort used may possibly be perceived as small; however, even in this cohort, differences were uncovered when making comparisons between the CVD risk algorithms.
Comparison with existing literature
Validation studies predicting absolute risk have reported that the NICE version of the Framingham Equation can overestimate risk by up to 5% in males, and shows poor calibration with females in comparison with QRISK2.18 It is unsurprising, therefore, that differences were also observed between numbers of individuals in different risk categories. In terms of absolute risk, however, only a 2.5% higher estimation was observed when comparing Framingham Lipids and QRISK2 in males. Comparisons between males using QRISK2 and Framingham BMI resulted in a 5% higher prediction in the latter risk equation, which may suggest some reliance on lipid profiles in more accurate CVD risk estimation, although the average male JBS2 median value is also 5% greater than the QRISK2 score and the Framingham BMI and JBS2 female average risk estimates are double that of QRISK2. An interesting observation is that, in relative terms, the older risk engines predicted risk to be higher than the more recent or updated equations. Healthcare professionals should account for this when determining which equation they deem ‘most appropriate’. Despite these observations, however, research has reported that six cardiovascular risk algorithms performed equally well in terms of screening performance even when differences were witnessed in false-positive rates between the equations.6 Three of these risk equations (QRISK2, Framingham General Cardiovascular Risk Profile [Framingham Lipids and Framingham BMI]) analysed in that research were adopted in this study, further justifying their selection. It appears that all the risk equations adopted in the present study have their own individual merits for selection; however, the reported better accuracy of absolute risk in the QRISK2 model after independent validation18 may enhance this risk equation for prioritisation in this Welsh population.
Implications for research and practice
From the observations in this study and the strong evidence of better accuracy, the QRISK2 model should be recommended for use in primary care in the Welsh population in terms of primary prevention of CVD. The added benefit to the QRISK2 model is that it is updated annually with the latest available routinely collected data from England and Wales. The variations in estimation of absolute risk could lead to ‘overtreatment’, where individuals are treated when their risk is substantially lower and vice versa. In both these scenarios there is a financial implication, be it by an increase in emergency admissions for individuals who believed they were at ‘low’ or ‘intermediate’ risk, or through statin treatments that are not required. One of the disadvantages of CVD risk prediction models is that the most heavily weighted variable in their algorithms is age,6,19 which explains how an increase in predicted CVD risk concomitant with age was observed with all the risk algorithms despite very small differences between the prevalence of isolated risk factors.
The shortcoming to this approach is that younger individuals (males <50 years, females <65 years) with a number of risk factors for developing CVD may not reach the thresholds required to be prescribed medication to reduce their risk.20 This is an important consideration in males as premature coronary heart disease is primarily caused by the combination of systolic hypertension, high concentrations of total cholesterol, and smoking.7 The other limitation to the heavy weighting for age is that older individuals with a single risk factor for CVD would score above the thresholds and be recommended for pharmacological intervention. It could be argued that management of isolated risk factors, rather than treatment initiated at an absolute predicted risk value, is more important. It will be interesting in time to observe whether the emergence of ‘lifetime’ risk models such as the QIntervention and the in-development JBS3 risk equations will improve CVD prediction and primary treatment. Unlike some type 2 diabetes prediction models that include other lifestyle factors, such as physical activity 21,22 and/or dietary habits,21 CVD equations only account for smoking. If included in CVD risk prediction, such factors would provide the opportunity for more relevant advice to be provided to individuals for lifestyle changes that could reduce CVD risk.
Acknowledgments
The Prosiect Sir Gâr Group is: Kerry Morgan, Chris Cottrell, Vanessa Davies, Liz Newbury-Davies, Michael Thomas, Enzo M Di Battista, Lesley Street, Fiona Judd, Cindy Evans, Jo James, Claire Jones, Carolyn Williams, Susan Smith, James Thornton, Sally P Williams, Rhys Williams, Sam Rice, Jeffrey W Stephens, and Meurig Williams.
Notes
Funding
This work was part-funded by the European Social Fund (ESF) through the European Union’s Convergence programme administered by the Welsh Government. Prosiect Sir Gâr received funding contributions from TATA, Hywel Dda Health Board (Diabetes Charitable Fund and Carmarthenshire Charitable Fund), Carmarthenshire County Council, and the following pharmaceutical companies; Takada, Lilly, Sanofi-Aventus, Boehringer-Ingelheim, Pfizer, and AstraZeneca.
Ethical approval
This study was approved by Dyfed Powys local research ethics committee (reference number: 11/WA/0101).
Provenance
Freely submitted; externally peer reviewed.
Competing interests
The authors have declared no competing interests.
Discuss this article
Contribute and read comments about this article: bjgp.org.uk/letters
- Received March 28, 2014.
- Revision requested June 10, 2014.
- Accepted July 1, 2014.
- © British Journal of General Practice 2014
REFERENCES
In this issue









Jump to section
More in this TOC Section
Related Articles
Cited By...

